Latent Consistency Model (LCM) have recently exploded over the internet and all the rage right now is about getting closer to real-time image generation where the image is generated and re-generated as you update your prompt.
Recent releases has come out with LCM models and LoRAs which you can use for creating images that only require as little as 4 steps to create. This means that your images are produced much faster and in my case I have seen them appear in under one second. If you want to learn more about my custom PC setup check out my post on this.
Models
LCM SDXL – Full weight for Latent Consistency Model distilled SDXL. You can produce images with only 2-8 inference steps. There are two model weights available FP16 version which is about 5GB and full weight which is tad over 10GB (in safetensors format). Yeah you might say that these are much bigger but bigger is better and faster!!
LCM SSD 1B – Full weights for Latent Consistency Model distilled SSD-1B which is an already distilled SDXL model. This model reduces the inference steps to 2-8 steps. There are two model files for this version as well, both are safetensors and come in a FP16 version at just over 2.5GB and full weights at just over 5GB in size.
The larger files have more data and will produce more higher quality image.
LoRAs
LCM LoRA SDXL – This is a distilled consistency adapter for SDXL Base 1.0 model and will reduce the number of inference steps between 2-8 steps. You can use this LoRA like any normal LoRA in your workflow with any SDXL model that is trained on the base model. The file available as safetensors is only 394Mb.
LCM LoRA SDv1.5 – This distilled consistency adapter is for SD v1.5 model and will reduce inference steps between 2-8 steps as well. You can use it with any SD v1.5 based standard or fine-tuned model. The file available is only 135Mb and is a safetensors version.
Using LoRAs in ComfyUI
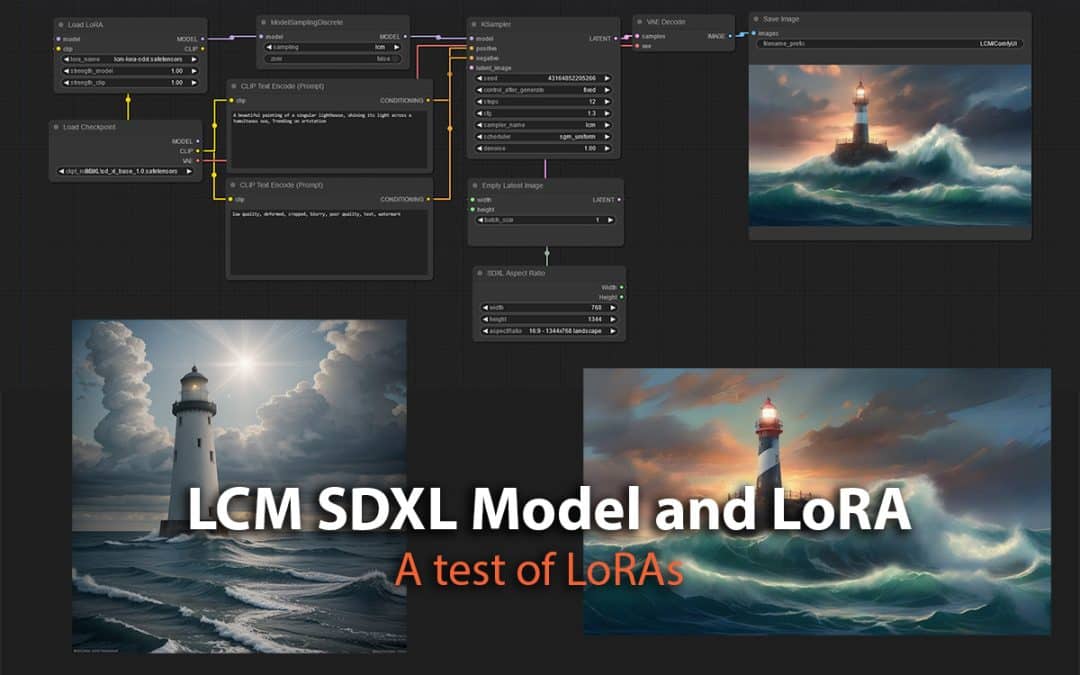
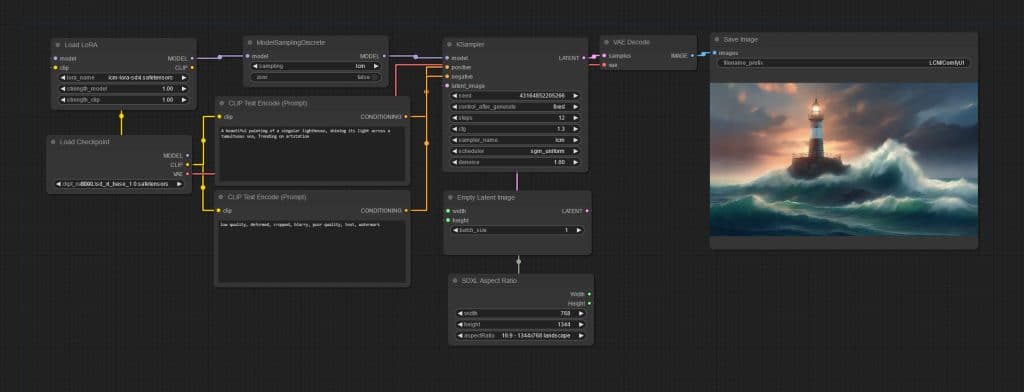
I built a workflow to try and use these LoRAs in ComfyUI. First I started with the SDXL using Base 1.0 model with LCM LoRA SDXL and ran a test with same prompt and seed but varying steps from 2, 4, 8 and 12. I set the CFG Scale to 1.3, it recommended to keep this low between 1 and 2. Seed used for the below images was constant 43164852205266. Resolution 1344 by 768.




Now with SD v1.5 model “epic realism natural” and the LCM LoRA SDv1.5, I repeated the above with 2, 4, 8 and 12 steps. Same seed and CFG only this time size is 512 by 512 px.




Results with SDXL LoRA start to be acceptable quality at 4 steps and above in my view where as with SD v1.5 LoRA you really do need to go to 8 steps to have a image that looks quite acceptable quality.
In this post we only test the LoRAs but in my next post I will test with the actual Models as well.
Of course the LCM quality is not as good as using the original Base models with higher steps but this sets up the technology to further evolve and get close to real-time generation. I am already seeing applications of this in various tools to produce images as you sketch on a canvas a very rough and brute drawing, combining that with text prompt it will create the resulting image in a second.
If you'd like to support our site please consider buying us a Ko-fi, grab a product or subscribe. Need a faster GPU, get access to fastest GPUs for less than $1 per hour with RunPod.io
Thank you for your posts!