
Inspired by a post by @rainisto where he shared how he created an AI character (women) using Midjourney and then trained a Stable Diffusion (SD) v1.5 Low Rank Adaptation (LoRA) so that you can create consistent character of the women in different settings.
This re-kindled the idea where I’ve been meaning to create fictional character that will play the main character in stories that I will create with my daughter and eventually converted to comics using SD created images. The challenge has always been how to get a consistent character in SD.
So I followed the post of @rainisto to start creating my character in Midjourney. She a 5 year old girl so I created many images in Midjourney. Here are a handful of images but I ended up with total of 30 images of which I chose 14 images to train my LoRA.

Next I searched the web for a video Tutorial which would help me decipher the world of Kohya SS Lora training WebUI.
I found this very well explained and detailed video. It covers all aspects of installation, setup and how to get going with Kohya.
The settings explained in this video were really handy for me and I opted to use the recommended settings. I share my settings below, you can download and save them as .JSON file. After this you can load it in Kohya.
{
"LoRA_type": "Standard",
"adaptive_noise_scale": 0,
"additional_parameters": "",
"block_alphas": "",
"block_dims": "",
"block_lr_zero_threshold": "",
"bucket_no_upscale": true,
"bucket_reso_steps": 64,
"cache_latents": true,
"cache_latents_to_disk": false,
"caption_dropout_every_n_epochs": 0.0,
"caption_dropout_rate": 0,
"caption_extension": "",
"clip_skip": "1",
"color_aug": false,
"conv_alpha": 1,
"conv_block_alphas": "",
"conv_block_dims": "",
"conv_dim": 1,
"decompose_both": false,
"dim_from_weights": false,
"down_lr_weight": "",
"enable_bucket": true,
"epoch": 12,
"factor": -1,
"flip_aug": false,
"full_bf16": false,
"full_fp16": false,
"gradient_accumulation_steps": "1",
"gradient_checkpointing": false,
"keep_tokens": "0",
"learning_rate": 0.0001,
"logging_dir": "C:/AI/Training/Girl-lora/log",
"lora_network_weights": "",
"lr_scheduler": "cosine",
"lr_scheduler_args": "",
"lr_scheduler_num_cycles": "",
"lr_scheduler_power": "",
"lr_warmup": "10",
"max_bucket_reso": 2048,
"max_data_loader_n_workers": "0",
"max_resolution": "512,512",
"max_timestep": 1000,
"max_token_length": "75",
"max_train_epochs": "",
"max_train_steps": "",
"mem_eff_attn": false,
"mid_lr_weight": "",
"min_bucket_reso": 256,
"min_snr_gamma": 0,
"min_timestep": 0,
"mixed_precision": "fp16",
"model_list": "custom",
"module_dropout": 0,
"multires_noise_discount": 0,
"multires_noise_iterations": 0,
"network_alpha": 1,
"network_dim": 128,
"network_dropout": 0,
"no_token_padding": false,
"noise_offset": 0,
"noise_offset_type": "Original",
"num_cpu_threads_per_process": 2,
"optimizer": "AdamW8bit",
"optimizer_args": "",
"output_dir": "C:/AI/Training/Girl-lora/model",
"output_name": "wwaa-g13l-1",
"persistent_data_loader_workers": false,
"pretrained_model_name_or_path": "\"C:\\AI\\models\\Stable-diffusion\\v1-5-pruned-emaonly.safetensors\"",
"prior_loss_weight": 1.0,
"random_crop": false,
"rank_dropout": 0,
"reg_data_dir": "C:/AI/Training/Girl-lora/reg",
"resume": "",
"sample_every_n_epochs": 0,
"sample_every_n_steps": 0,
"sample_prompts": "",
"sample_sampler": "euler_a",
"save_every_n_epochs": 1,
"save_every_n_steps": 0,
"save_last_n_steps": 0,
"save_last_n_steps_state": 0,
"save_model_as": "safetensors",
"save_precision": "fp16",
"save_state": false,
"scale_v_pred_loss_like_noise_pred": false,
"scale_weight_norms": 0,
"sdxl": false,
"sdxl_cache_text_encoder_outputs": false,
"sdxl_no_half_vae": true,
"seed": "",
"shuffle_caption": false,
"stop_text_encoder_training": 0,
"text_encoder_lr": 5e-05,
"train_batch_size": 1,
"train_data_dir": "C:/AI/Training/Girl-lora/img",
"train_on_input": true,
"training_comment": "",
"unet_lr": 0.0001,
"unit": 1,
"up_lr_weight": "",
"use_cp": false,
"use_wandb": false,
"v2": false,
"v_parameterization": false,
"v_pred_like_loss": 0,
"vae_batch_size": 0,
"wandb_api_key": "",
"weighted_captions": false,
"xformers": "xformers"
}Using these settings I setup my Kohya and clicked on Start training.
Memory usage on my RTX4080 was quite low based on these settings and using a 512x512px dataset. It was hovering around 40% usage when I checked the Task Manager which leads me to believe around 6-7Gb of my 16Gb total total GPU memory.
This leads to be feel confident that I can push LoRA training for SDXL as well if I want to explore this but that will be future post.
Once the LoRA training is finished you need to move the model files generated by Kohya (.safetensors) into the Stable Diffusion Web UI directory under models\Lora folder. If you want to learn about how I organise my models then check out my tips and tricks on SD
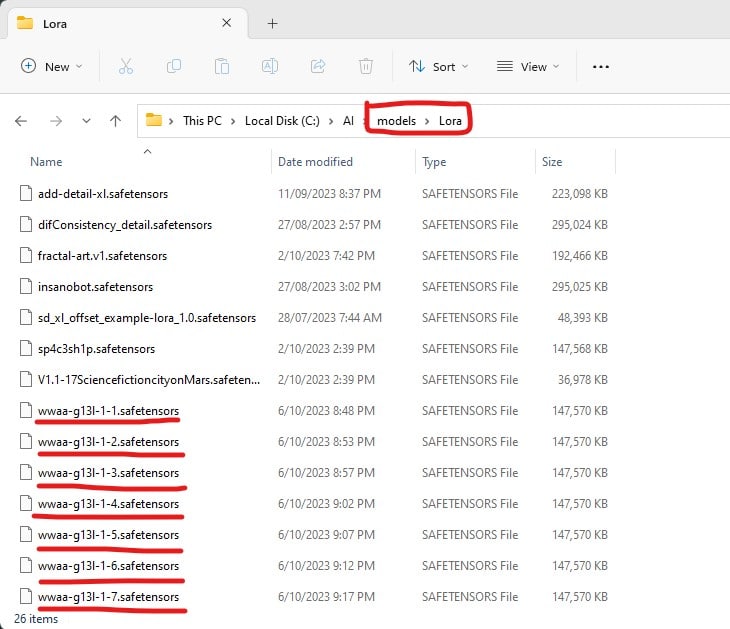
Once you have copied these files then its worth plotting an XYZ plot to see what difference the different LoRA make to your images. As I had 12 different version I decided to try only the EVEN versions and also compare against various CFG scale values.
Defining in the Prompt S/R in my X axis: chk,2,4,6,8,10,12
Defining the CFG Scale in my Y axis: 7,8,9,10
The prompt is: anime, comic, cartoon, portrait of a girl <lora:wwaa-g13l-1-chk:1>, illustration, dark hair
The CHK variable is what the Prompt S/R which is search and replace will look for and replace with values 2, 4, 6 and so on.

The resulting grid looks something like this. The first row is where the value is NULL so its the standard model output at various different CFG scales. The second row and beyond, you see the character come to life and resembles close to the girl that I had generated using Midjourney. If I do more experimentation and fine-tuning of the LoRA it probable could get close.
However the goal of this was to create a LoRA that allows me to get consistent character each seed after another. Below grid is with a locked seed but you will see sample further below that are with varying seed.

Reviewing the images above you can decide which version of the LoRA you wish to use in your generations. In my opinion version #8 looks pretty nice to me, so I will keep this and archive the other versions.
To verify that I am getting the same character with each image, I run the above prompt as a batch with my chosen LoRA #8

Conclusion
Finally to summarise, I’m happy with my very first experiment that achieved two results for me: one – I got to learn and discover how to train my own LoRA using a set of images; and two – I got to create a fictitious character that will help me develop further projects that I had been meaning to do.
Thanks to @rainisto for sharing his wonderful tutorial on X. If you are on X (aka Twitter) then go give him a follow and check out his content. There is such a wonderful community there which shares its learning in the AI space, so we all learn & grow together.
Questions or comments welcome!
If you'd like to support our site please consider buying us a Ko-fi, grab a product or subscribe. Need a faster GPU, get access to fastest GPUs for less than $1 per hour with RunPod.io
Trackbacks/Pingbacks