
Last week has been incredible with the release of some really cool updates in the AI space, most notably the one getting least attention at the moment is Stable Cascade.
git clone https://huggingface.co/spaces/multimodalart/stable-cascade
cd Stable-Cascade
python -m venv env
env\Scripts\activate
pip install gradio
pip install torch torchvision torchaudio xformers --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txtOnce the installation is complete review the errors, if you are on Windows you are likely to get ModuleNotFoundError: No module named 'triton', if you get this don’t worry it will still work and run. This is a known limitation as Triton is not compiled for Windows OS. I got this error and my instance still runs.
Edit and replace the app.py with my modified version. This includes changes so that your local instance will run.
#Modified version of the original App.py from https://huggingface.co/spaces/multimodalart/stable-cascade by https://weirdwonderfulai.art team
import os
import random
import gradio as gr
import numpy as np
import PIL.Image
import torch
from typing import List
from diffusers.utils import numpy_to_pil
from diffusers import StableCascadeDecoderPipeline, StableCascadePriorPipeline
from diffusers.pipelines.wuerstchen import DEFAULT_STAGE_C_TIMESTEPS
#import spaces
from previewer.modules import Previewer
#import user_history
os.environ['TOKENIZERS_PARALLELISM'] = 'false'
DESCRIPTION = "# Stable Cascade"
DESCRIPTION += "\n<p style=\"text-align: center\">Unofficial demo for <a href='https://huggingface.co/stabilityai/stable-cascade' target='_blank'>Stable Cascade</a>, a new high resolution text-to-image model by Stability AI, built on the Würstchen architecture - <a href='https://huggingface.co/stabilityai/stable-cascade/blob/main/LICENSE' target='_blank'>non-commercial research license</a></p>"
if not torch.cuda.is_available():
DESCRIPTION += "\n<p>Running on CPU 🥶</p>"
MAX_SEED = np.iinfo(np.int32).max
CACHE_EXAMPLES = False
MAX_IMAGE_SIZE = int(os.getenv("MAX_IMAGE_SIZE", "1536"))
USE_TORCH_COMPILE = False
ENABLE_CPU_OFFLOAD = os.getenv("ENABLE_CPU_OFFLOAD") == "1"
PREVIEW_IMAGES = True
dtype = torch.bfloat16
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
if torch.cuda.is_available():
prior_pipeline = StableCascadePriorPipeline.from_pretrained("stabilityai/stable-cascade-prior", torch_dtype=dtype)#.to(device)
decoder_pipeline = StableCascadeDecoderPipeline.from_pretrained("stabilityai/stable-cascade", torch_dtype=dtype)#.to(device)
if ENABLE_CPU_OFFLOAD:
prior_pipeline.enable_model_cpu_offload()
decoder_pipeline.enable_model_cpu_offload()
else:
prior_pipeline.to(device)
decoder_pipeline.to(device)
if USE_TORCH_COMPILE:
prior_pipeline.prior = torch.compile(prior_pipeline.prior, mode="reduce-overhead", fullgraph=True)
decoder_pipeline.decoder = torch.compile(decoder_pipeline.decoder, mode="max-autotune", fullgraph=True)
if PREVIEW_IMAGES:
previewer = Previewer()
previewer_state_dict = torch.load("previewer/previewer_v1_100k.pt", map_location=torch.device('cpu'))["state_dict"]
previewer.load_state_dict(previewer_state_dict)
def callback_prior(i, t, latents):
output = previewer(latents)
output = numpy_to_pil(output.clamp(0, 1).permute(0, 2, 3, 1).float().cpu().numpy())
return output
callback_steps = 1
else:
previewer = None
callback_prior = None
callback_steps = None
else:
prior_pipeline = None
decoder_pipeline = None
def randomize_seed_fn(seed: int, randomize_seed: bool) -> int:
if randomize_seed:
seed = random.randint(0, MAX_SEED)
return seed
#@spaces.GPU
def generate(
prompt: str,
negative_prompt: str = "",
seed: int = 0,
width: int = 1024,
height: int = 1024,
prior_num_inference_steps: int = 30,
# prior_timesteps: List[float] = None,
prior_guidance_scale: float = 4.0,
decoder_num_inference_steps: int = 12,
# decoder_timesteps: List[float] = None,
decoder_guidance_scale: float = 0.0,
num_images_per_prompt: int = 2,
#profile: gr.OAuthProfile | None = None,
) -> PIL.Image.Image:
previewer.eval().requires_grad_(False).to(device).to(dtype)
prior_pipeline.to(device)
decoder_pipeline.to(device)
generator = torch.Generator().manual_seed(seed)
#print("prior_num_inference_steps: ", prior_num_inference_steps)
prior_output = prior_pipeline(
prompt=prompt,
height=height,
width=width,
num_inference_steps=prior_num_inference_steps,
timesteps=DEFAULT_STAGE_C_TIMESTEPS,
negative_prompt=negative_prompt,
guidance_scale=prior_guidance_scale,
num_images_per_prompt=num_images_per_prompt,
generator=generator,
callback=callback_prior,
callback_steps=callback_steps
)
if PREVIEW_IMAGES:
for _ in range(len(DEFAULT_STAGE_C_TIMESTEPS)):
r = next(prior_output)
if isinstance(r, list):
yield r[0]
prior_output = r
decoder_output = decoder_pipeline(
image_embeddings=prior_output.image_embeddings,
prompt=prompt,
num_inference_steps=decoder_num_inference_steps,
# timesteps=decoder_timesteps,
guidance_scale=decoder_guidance_scale,
negative_prompt=negative_prompt,
generator=generator,
output_type="pil",
).images
#Save images
#for image in decoder_output:
# user_history.save_image(
# profile=profile,
# image=image,
# label=prompt,
# metadata={
# "negative_prompt": negative_prompt,
# "seed": seed,
# "width": width,
# "height": height,
# "prior_guidance_scale": prior_guidance_scale,
# "decoder_num_inference_steps": decoder_num_inference_steps,
# "decoder_guidance_scale": decoder_guidance_scale,
# "num_images_per_prompt": num_images_per_prompt,
# },
# )
yield decoder_output[0]
examples = [
"An astronaut riding a green horse",
"A mecha robot in a favela by Tarsila do Amaral",
"The sprirt of a Tamagotchi wandering in the city of Los Angeles",
"A delicious feijoada ramen dish"
]
with gr.Blocks() as demo:
gr.Markdown(DESCRIPTION)
gr.DuplicateButton(
value="Duplicate Space for private use",
elem_id="duplicate-button",
visible=os.getenv("SHOW_DUPLICATE_BUTTON") == "1",
)
with gr.Group():
with gr.Row():
prompt = gr.Text(
label="Prompt",
show_label=False,
max_lines=1,
placeholder="Enter your prompt",
container=False,
)
run_button = gr.Button("Run", scale=0)
result = gr.Image(label="Result", show_label=False)
with gr.Accordion("Advanced options", open=False):
negative_prompt = gr.Text(
label="Negative prompt",
max_lines=1,
placeholder="Enter a Negative Prompt",
)
seed = gr.Slider(
label="Seed",
minimum=0,
maximum=MAX_SEED,
step=1,
value=0,
)
randomize_seed = gr.Checkbox(label="Randomize seed", value=True)
with gr.Row():
width = gr.Slider(
label="Width",
minimum=1024,
maximum=MAX_IMAGE_SIZE,
step=512,
value=1024,
)
height = gr.Slider(
label="Height",
minimum=1024,
maximum=MAX_IMAGE_SIZE,
step=512,
value=1024,
)
num_images_per_prompt = gr.Slider(
label="Number of Images",
minimum=1,
maximum=2,
step=1,
value=1,
)
with gr.Row():
prior_guidance_scale = gr.Slider(
label="Prior Guidance Scale",
minimum=0,
maximum=20,
step=0.1,
value=4.0,
)
prior_num_inference_steps = gr.Slider(
label="Prior Inference Steps",
minimum=10,
maximum=30,
step=1,
value=20,
)
decoder_guidance_scale = gr.Slider(
label="Decoder Guidance Scale",
minimum=0,
maximum=0,
step=0.1,
value=0.0,
)
decoder_num_inference_steps = gr.Slider(
label="Decoder Inference Steps",
minimum=4,
maximum=12,
step=1,
value=10,
)
gr.Examples(
examples=examples,
inputs=prompt,
outputs=result,
fn=generate,
cache_examples=CACHE_EXAMPLES,
)
inputs = [
prompt,
negative_prompt,
seed,
width,
height,
prior_num_inference_steps,
# prior_timesteps,
prior_guidance_scale,
decoder_num_inference_steps,
# decoder_timesteps,
decoder_guidance_scale,
num_images_per_prompt,
]
gr.on(
triggers=[prompt.submit, negative_prompt.submit, run_button.click],
fn=randomize_seed_fn,
inputs=[seed, randomize_seed],
outputs=seed,
queue=False,
api_name=False,
).then(
fn=generate,
inputs=inputs,
outputs=result,
api_name="run",
)
with gr.Blocks(css="style.css") as demo_with_history:
with gr.Tab("App"):
demo.render()
#with gr.Tab("Past generations"):
# user_history.render()
if __name__ == "__main__":
demo_with_history.queue(max_size=20).launch()After saving the App.py you can launch the application by running the below commands, you can copy & paste them in .BAT file and have it run as a script.
cd Stable-Cascade
env\Scripts\activate
python app.pyThe command line will run up the Gradio app with the URL http://127.0.0.1:7860/, open that in your browser and start creating.
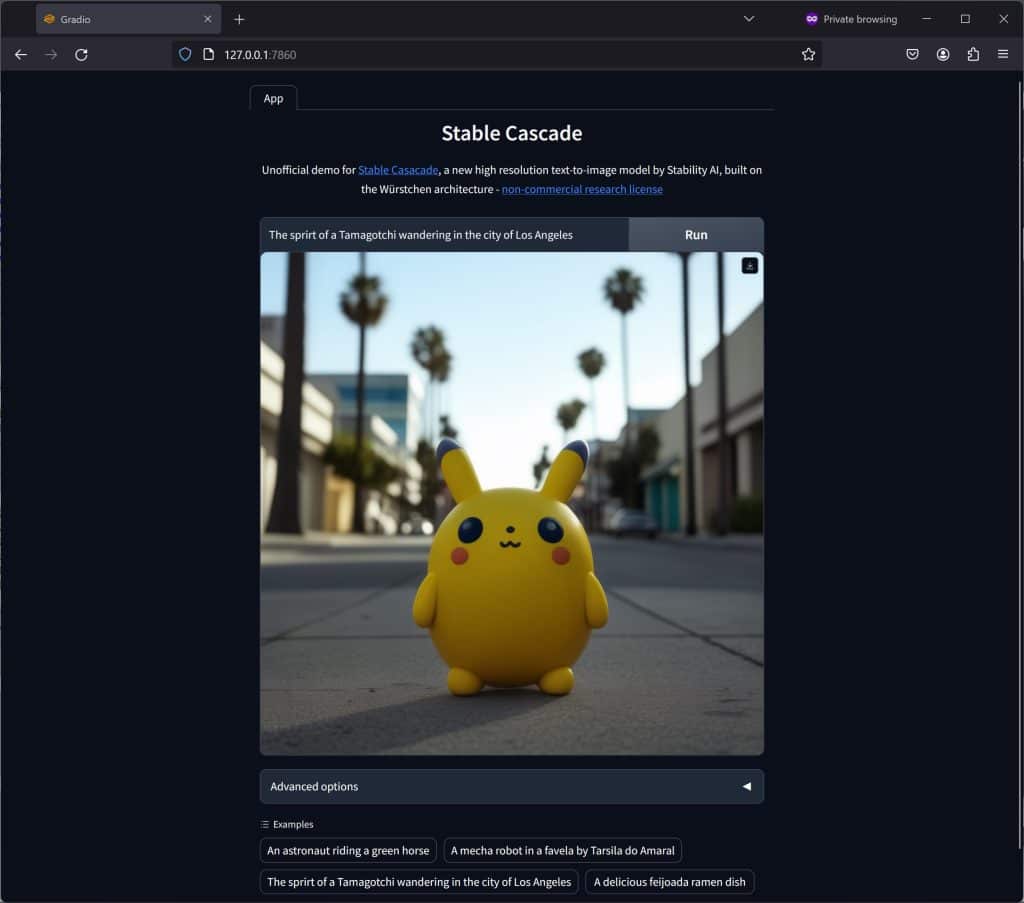
If you are curious on how to use this UX, then check out my video where I shared how (showing the online free version but both local and online works the same).
Conclusion
Really enjoying the aesthetics and prompt coherence with Stable Cascade, it feels like to understands better the natural language and produces more well composed images as a result. Have to say its pretty good at handling text as you can see below. I’d love to experiment more as this get further implemented in Automatic1111 and ComfyUI in the coming weeks.
A few samples from this implementation which I have running on my PC.






If you'd like to support our site please consider buying us a Ko-fi, grab a product or subscribe. Need a faster GPU, get access to fastest GPUs for less than $1 per hour with RunPod.io
(env) D:\ai\stable-cascade>python app.py
[‘D:\\ai\\stable-cascade\\env’, ‘D:\\ai\\stable-cascade\\env\\lib\\site-packages’]
WARNING[XFORMERS]: xFormers can’t load C++/CUDA extensions. xFormers was built for:
PyTorch 2.2.2+cu121 with CUDA 1201 (you have 2.2.2+cpu)
Python 3.10.11 (you have 3.10.4)
Please reinstall xformers (see https://github.com/facebookresearch/xformers#installing-xformers)
Memory-efficient attention, SwiGLU, sparse and more won’t be available.
Set XFORMERS_MORE_DETAILS=1 for more details
Traceback (most recent call last):
File “D:\ai\stable-cascade\app.py”, line 16, in
from previewer.modules import Previewer
ModuleNotFoundError: No module named ‘previewer’
can you help me, how to solve this problem?
You need to install the compatible version. Based on the error it should be this one:
pip3 install -U xformers –index-url https://download.pytorch.org/whl/cu121
Run this command under the venv after you activate it.