
Stable Diffusion is the new kid on the block and has adopted the Discord bot style approach of Midjourney to create AI generated images. Stable Diffusion is created by Stability.AI in order to disrupt and compete with Dall-e models. The licensing of Stable Diffusion is CC0 1.0 Universal Public Domain Dedication available at (https://creativecommons.org/publicdomain/zero/1.0/)
In order to be able to access Stable Diffusion you need to register for the Official Beta and wait for your invitation. It took us 5 weeks to gain access so patience is key.
So far what we know about Stable Diffusion is that its fast!! In comparison incredibly fast when compared to others like Dall-e, Midjourney and is designed in a way that it can run easily on low end GPU (Graphic Processor Unit). Eventually it will be available openly to everyone most likely via Google Colabs as well, this is what we have concluded from various discussions and threads on Twitter.
Having played and use d many different tools that create AI art from text, Stable Diffusion is quiet amazing with it composition and details, especially faces. No other AI has been able to produce such nicely composed facial features as I have seen with Stable Diffusion.

Sci-fi and illustrations created using Stable Diffusion are so pleasing, you can see how nicely composed the two images below are. Especially the image with the house, check out the reflection!! 😮


Faces can come out more pleasing then ever seen before straight out of Stable Diffusion. I was super impressed with the below result, the proportion, features and the most difficult part the eyes are nicely generated by the AI. You can see the slight difference in the two eyes but it would be easily retouched in other software.

The UX of the Stable Diffusion, is quite basic – all the prompts parameters are text based and mostly everything is public there is no Private mode unlike Midjourney. There is no Upscale, create Variation. There was a switch -i which produced individual images but that is deprecated as of this week so generating multiple images can be be painful, especially because you can run one command per minute.
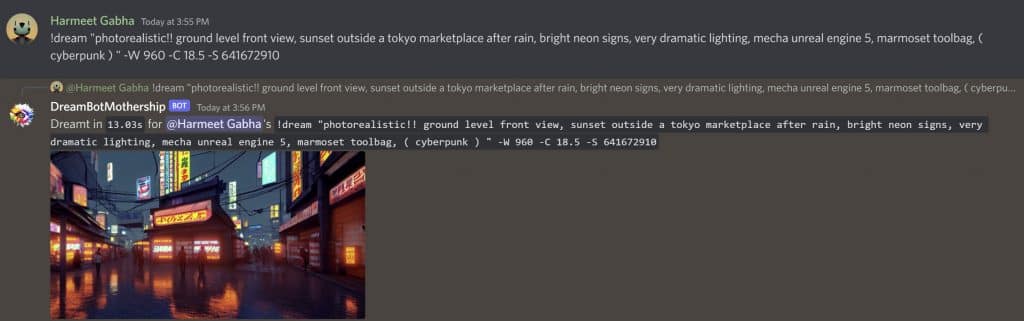
Despite the shortcoming, Stable Diffusion is producing some stunning images even though its in beta stage. I cant wait to see what is possible by the time it becomes publicly available to everyone.


If you'd like to support our site please consider buying us a Ko-fi, grab a product or subscribe. Need a faster GPU, get access to fastest GPUs for less than $1 per hour with RunPod.io